
[Android] 앱 아키텍처 가이드

모바일 앱 사용자 환경
OS에 의해 언제든지 앱 프로세스가 종료될 수 있다.
이러한 이벤트는 직접 제어할 수 없다. 그렇기 때문에 앱 구성요소에 데이터나 상태를 저장해서는 안되며, 서로 종속되면 안된다.
안정성을 보장 받을 수 없기때문에.
일반 아키텍처 원칙
앱을 확장하고 견고성을 높이며, 더 쉽게 테스트할 수 있도록 ‘아키텍처’를 정의해야한다.
앱 아키텍처란 기능간의 정의이다.
관심사 분리
가장 중요한 원칙은 ‘관심사 분리’이다.
Acitivity, Fragment는
OS와 앱 사이의 계약을 나타내도록 이어주는 클래스일 뿐이다.
언제든지 OS에 의해 제거될 수 있다.
위의 내용으로 인해 이러한 클래스에 대한 의존성을 최소화해야한다.
UI 및 OS상호작용을 처리하는 로직만 포함해야 한다.
데이터 모델에서 UI 도출하기
데이터 모델에서 UI를 도출해야 한다.
데이터 모델은 앱의 데이터를 나타낸다.
UI 요소 및 기타 구성요소로 부터 독립적이다.
생명 주기와 관련 없다.
단일 소스 저장소
데이터 추가, 변경, 삭제는 단일 소스 저장소에서만 이루어져야한다.
모든 변경사항을 한곳으로 일원화한다.
다른 유형이 조작할 수 없도록 데이터를 보호한다.
데이터 변경사항을 더 쉽게 추적할 수 있도록하여 버그를 발견하기 쉬워진다.
단방향 데이터 흐름
상태와 데이터 흐름은 한방향으로만 흐른다.
데이터 일관성을 강화한다.
오류가 발생할 확률을 줄여준다.
디버그가 쉽다.
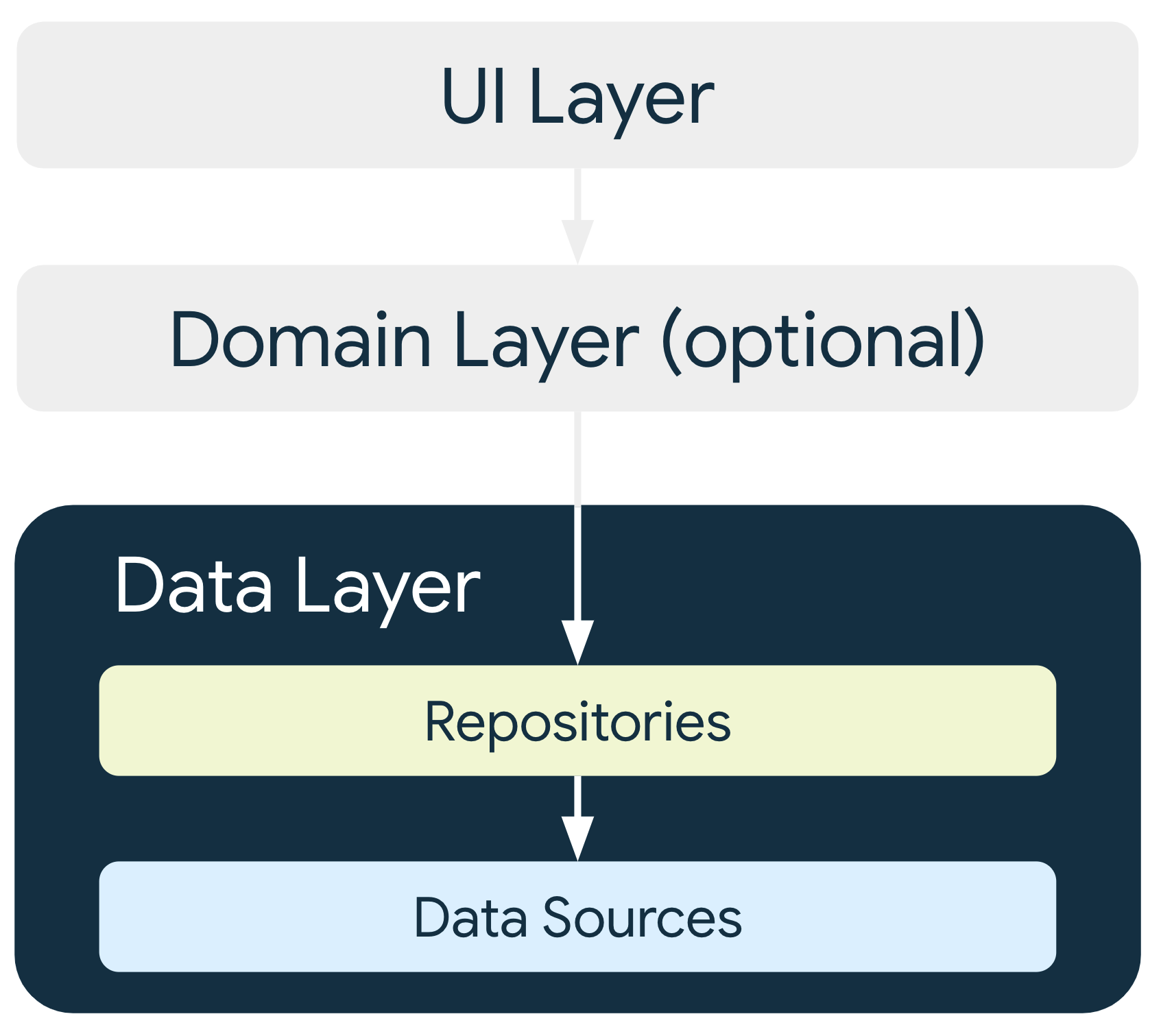
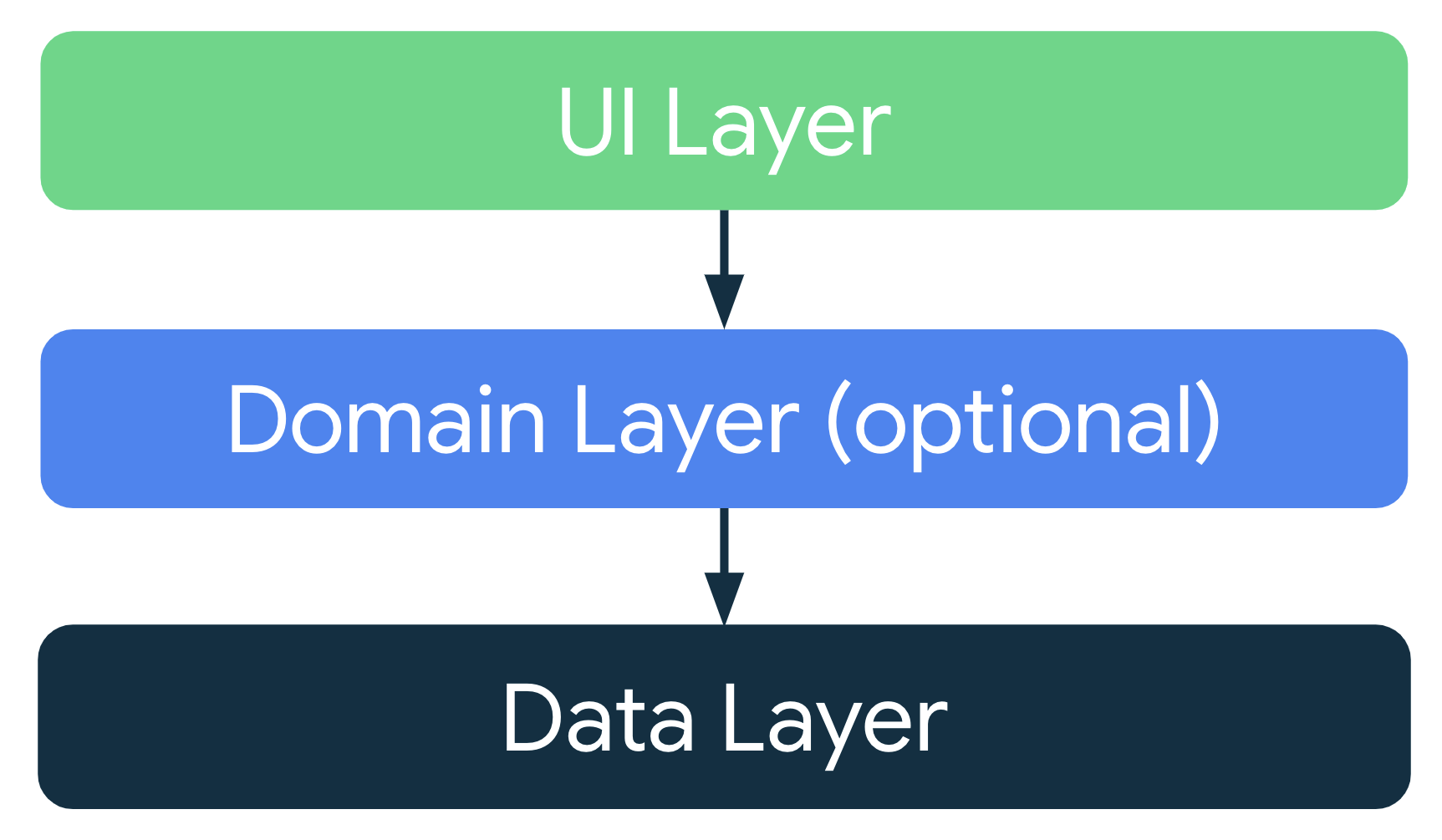
권장 앱 아키텍처
위의 원칙에 따라 최소한 다음 두 가지 레이어가 있어야한다.
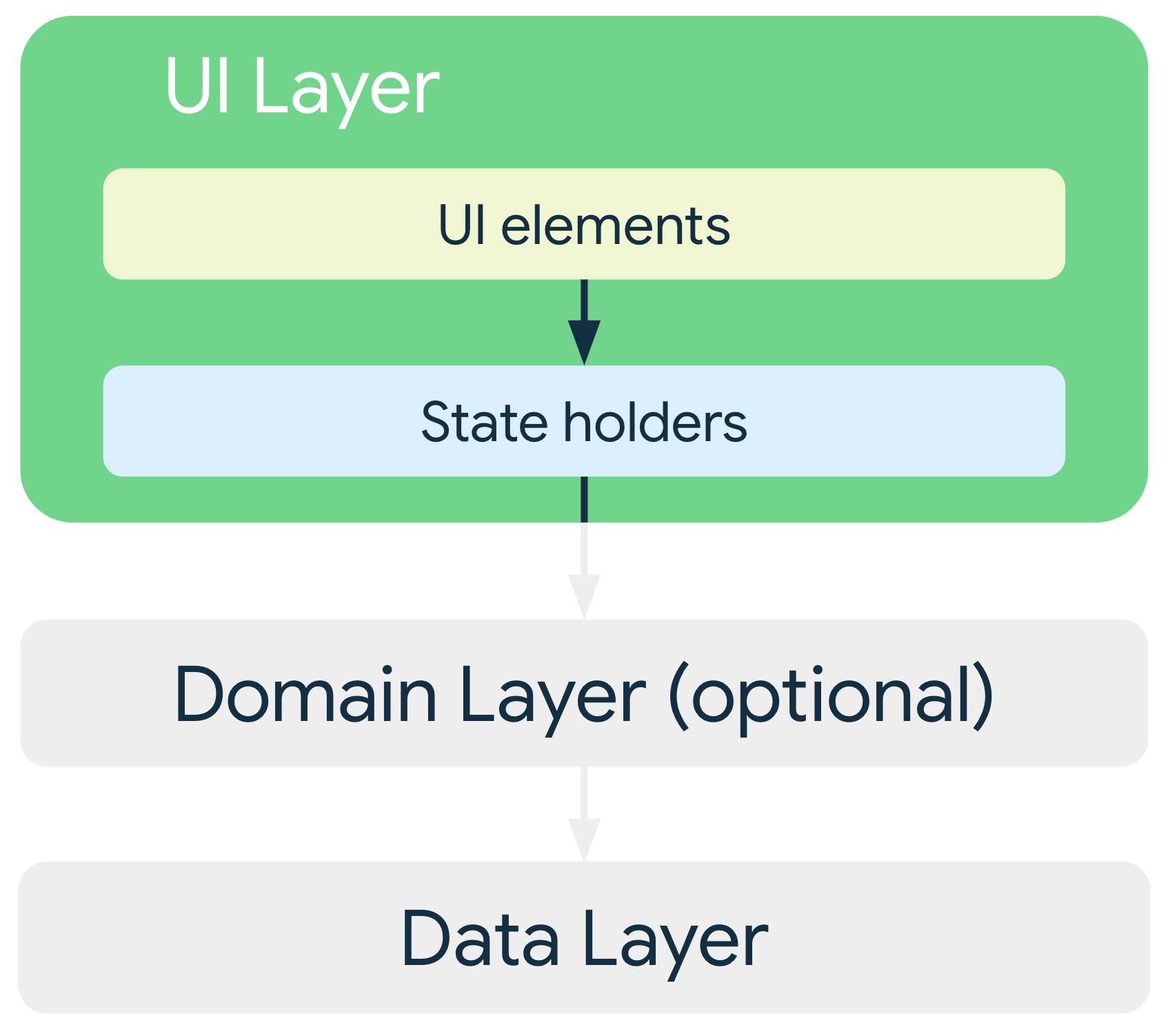
화면에 앱 데이터를 표시하는 UI 레이어
앱의 비즈니스 로직을 포함하고 앱 데이터를 노출하는 데이터 레이어
UI와 데이터 레이어 간의 상호작용을 간소화하고 재사용하기위해 도메인 레이어라는 레이어를 추가할 수 있다.
UI 레이어

UI의 역할은 화면에 데이터를 표시하고 사용자 상호작용의 기본지점
화면에 데이터를 렌더링하는 UI 요소
데이터를 보유하고 이를 UI에 노출하며 로직을 처리하는 상태홀더((ex)ViewModel 클래스)
UI 레이어 파이프 라인
- App data → UI data
- UI data → UI elements
- User events → UI Changes
- repeat
UI 상태 정의
UI 상태는 앱에서 사용자가 봐야 한다고 지정하는 항목
UI 상태가 변경되면 변경사항이 즉시 UI에 반영된다.
data class NewsUiState(
val isSignedIn: Boolean = false,
val isPremium: Boolean = false,
val newsItems: List<NewsItemUiState> = listOf(),
val userMessages: List<Message> = listOf()
)
data class NewsItemUiState(
val title: String,
val body: String,
val bookmarked: Boolean = false,
...
)
불변성
UI 상태 정의는 변경할 수 없다.
불변성으로 인해 객체가 순간의 상태를 보장한다.
UI에서 UI상태를 직접 수정해서는 안된다. (데이터 불일치, 미세한 버그 발생)
변경 불가능한 스냅샷
단방향 데이터 흐름으로 상태 관리
UI의 역할은 오직 UI 상태를 사용 및 표시하는것
상태 홀더
UI 상태를 생성하는 클래스
일반적으로 ViewModel의 인스턴스
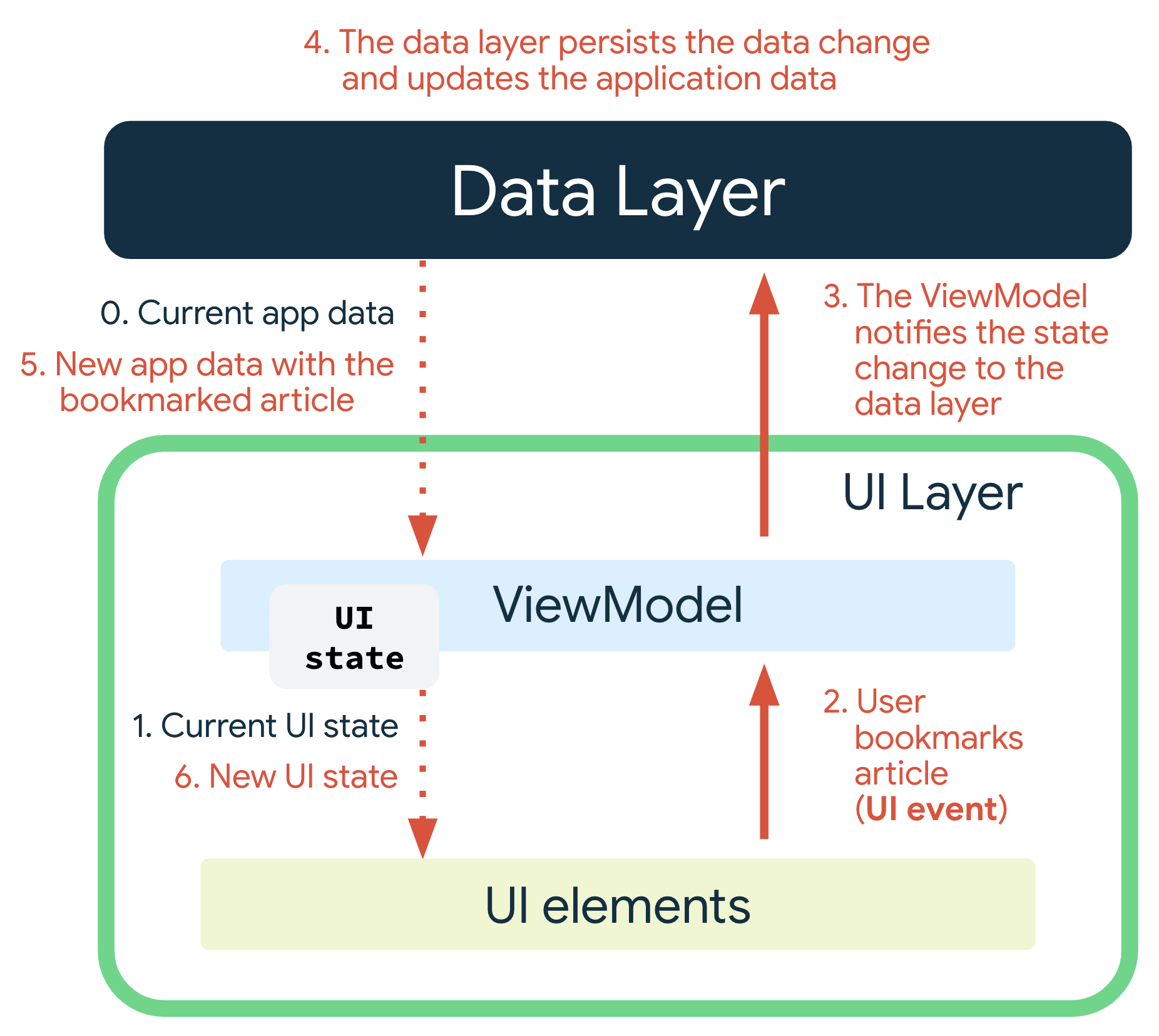
UI와 ViewModel 사이의 상호작용은 대체로 ‘이벤트 입력’과 입력의 후속 상태인 ‘출력’으로 간주될 수 있다.
상태가 아래로, 이벤트가 위로 향하는 패턴을 단방향 데이터 흐름(UDF)이라고 한다.
- ViewModel이 UI에 사용될 상태를 보유 및 노출, UI 상태는 ViewModel에 의해 변환된 앱 데이터이다.
- UI가 ViewModel에 사용자 이벤트를 알린다.
- ViewModel이 사용자 작업을 처리하고 상태를 업데이트한다.
- 업데이트된 상태가 렌더링할 UI에 다시 제공된다.
- 상태 변경을 야기하는 모든 이벤트에 위의 작업이 반복된다.
UDF를 사용하는 이유
- 데이터 일관성 : UI용 정보 소스가 하나이다.
- 테스트 가능성 : 상태 소스가 분리되므로 UI와 별개로 테스트할 수 있다.
- 유지 관리성 : 상태 변경은 잘 정의된 패턴을 따른다.
UI 상태 노출
UDF를 사용하여 상태 생성을 관리하므로 생성된 상태를 스트림으로 간주할 수 있다.
LiveData 또는 StateFlow와 같이 관찰 가능한 데이터 홀더에 UI 상태를 노출해야 한다.
class NewsViewModel(
private val repository: NewsRepository,
...
) : ViewModel() {
private val _uiState = MutableStateFlow(NewsUiState())
val uiState: StateFlow<NewsUiState> = _uiState.asStateFlow()
private var fetchJob: Job? = null
fun fetchArticles(category: String) {
fetchJob?.cancel()
fetchJob = viewModelScope.launch {
try {
val newsItems = repository.newsItemsForCategory(category)
_uiState.update {
it.copy(newsItems = newsItems)
}
} catch (ioe: IOException) {
// Handle the error and notify the UI when appropriate.
_uiState.update {
val messages = getMessagesFromThrowable(ioe)
it.copy(userMessages = messages)
}
}
}
}
}
- LiveData 와 StateFlow
- 공통점
- 관찰 가능한 데이터 홀더 클래스
- 앱 아키텍처에 사용할때 비슷한 패턴을 따름
- 차이점
- StateFlow는 초기 상태를 생성자에 전달해야함 LiveData는 전달하지 않음
- View가 Stopped상태가 되면 LiveData.observe()는 소비자를 자동으로 등록 취소
- StateFlow는 자동으로 수집을 중지하지 않음 동일한 동작을 하려면 Lifecycle.repeatOnLifecycle 블록에서 흐름을 수집해야함
- LiveData는 안드로이드 플랫폼에 종속적, StateFlow는 순수 Kolin 라이브러리로 Domain Layer에서 사용 가능
- 공통점
ViewModel의 이벤트는 즉시 UI 상태 업데이트로 소비되어야한다.
Channel이나 SharedFlow 같이 다른 옵션을 사용하면 이벤트 전달 및 처리가 보장되지 않는다.
UI가 백그라운드에 진입하면 Channel Collection이 멈추게되고 이벤트를 놓치게 된다.
도메인 레이어
복잡한 비즈니스 로직이나 여러 ViewModel에서 재사용되는 간단한 비즈니스 로직의 캡슐화를 담당
모든 앱에 이러한 요구사항이 있는 것은 아니므로 선택사항이다.
- 코드 중복 방지
- 도메인 레이어 클래스를 사용하는 클래스의 가독성을 개선
- 앱의 테스트 가능성을 높임
- 책임을 분할하여 대형 클래스를 피할 수 있음
간단하고 가볍게 유지하려면 기능 하나만 담당해야하고 변경 가능한 데이터를 포함해서는 안된다.
UI레이어 또는 데이터 레이어에서 변경 가능한 데이터를 처리해야 한다.
이 가이드의 이름 지정 규칙
각각 담당하고 있는 단일 작업에 따라 지정된다.
현재 시제의 동사 + 명사/대상(선택사항) + UseCase
예를들면 FormatDateUseCase, LogOutUserUseCase, MakeLoginRequestUseCase가 있다.
종속 항목
재사용 가능한 로직을 포함하기 때문에 다른 UseCase에 의해 사용될 수 있다.
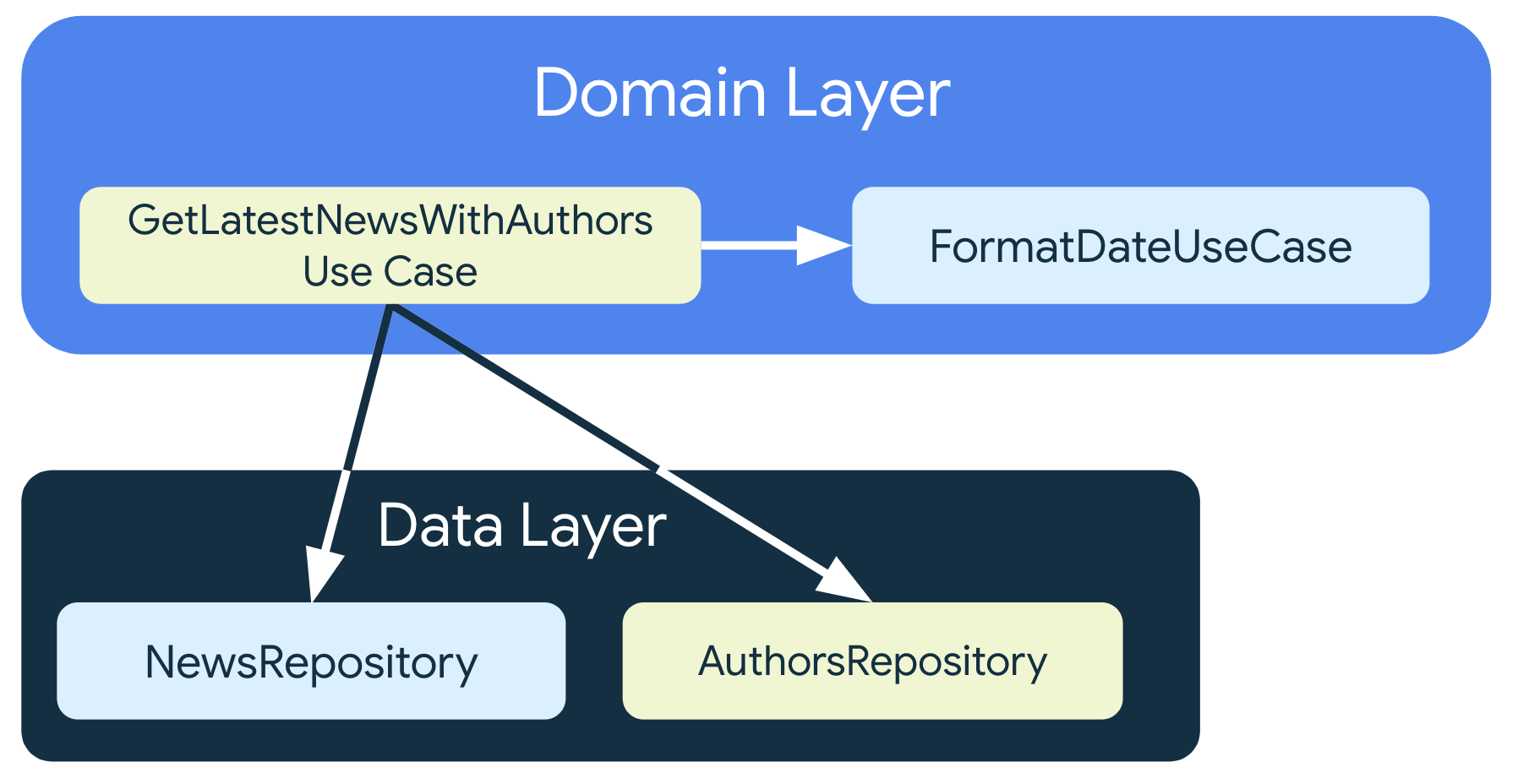
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository,
private val formatDateUseCase: FormatDateUseCase
) { /* ... */ }
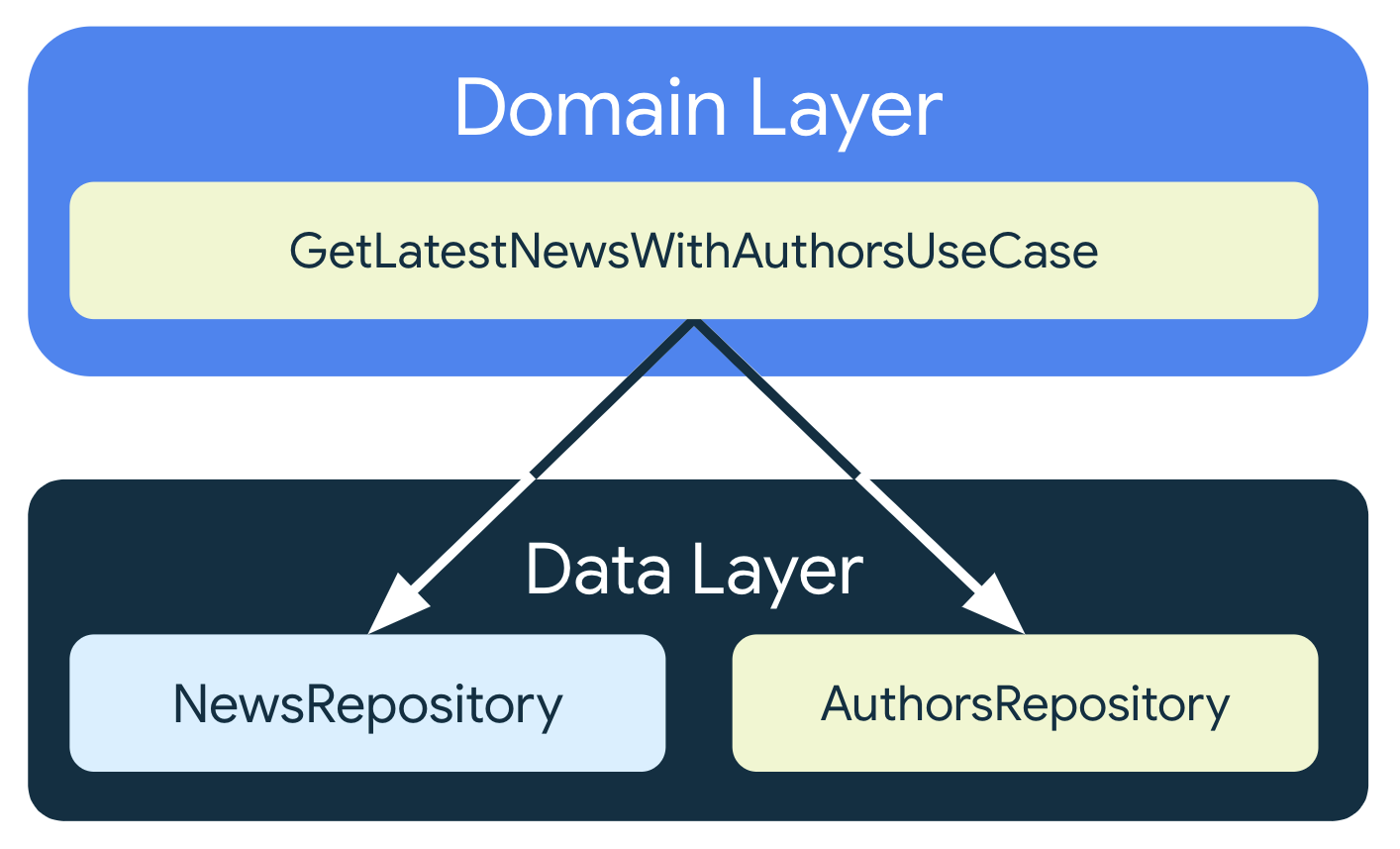
저장소 결합
여러 저장소에서 나오는 데이터를 조합해 UseCase를 만들 수 있다.
/**
* This use case fetches the latest news and the associated author.
*/
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend operator fun invoke(): List<ArticleWithAuthor> =
withContext(defaultDispatcher) {
val news = newsRepository.fetchLatestNews()
val result: MutableList<ArticleWithAuthor> = mutableListOf()
// This is not parallelized, the use case is linearly slow.
for (article in news) {
// The repository exposes suspend functions
val author = authorsRepository.getAuthor(article.authorId)
result.add(ArticleWithAuthor(article, author))
}
result
}
}
데이터 레이어
비즈니스 로직이 포함되고 데이터를 표출한다.
Repositories 클래스에서 담당하는 작업은 다음과 같다.
- 데이터 노출 - 일관성을 위해 노출된 데이터는 변경 불가능해야한다
- 데이터 변경사항을 한 곳에 집중
- 여러 데이터 소스 간의 충돌 해결
- 비즈니스 로직 포함
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
데이터 레이어의 진입점은 항상 레파지토리 클래스여야 한다.
데이터 소스가 직접 종속 항목으로 있어서는 안된다.
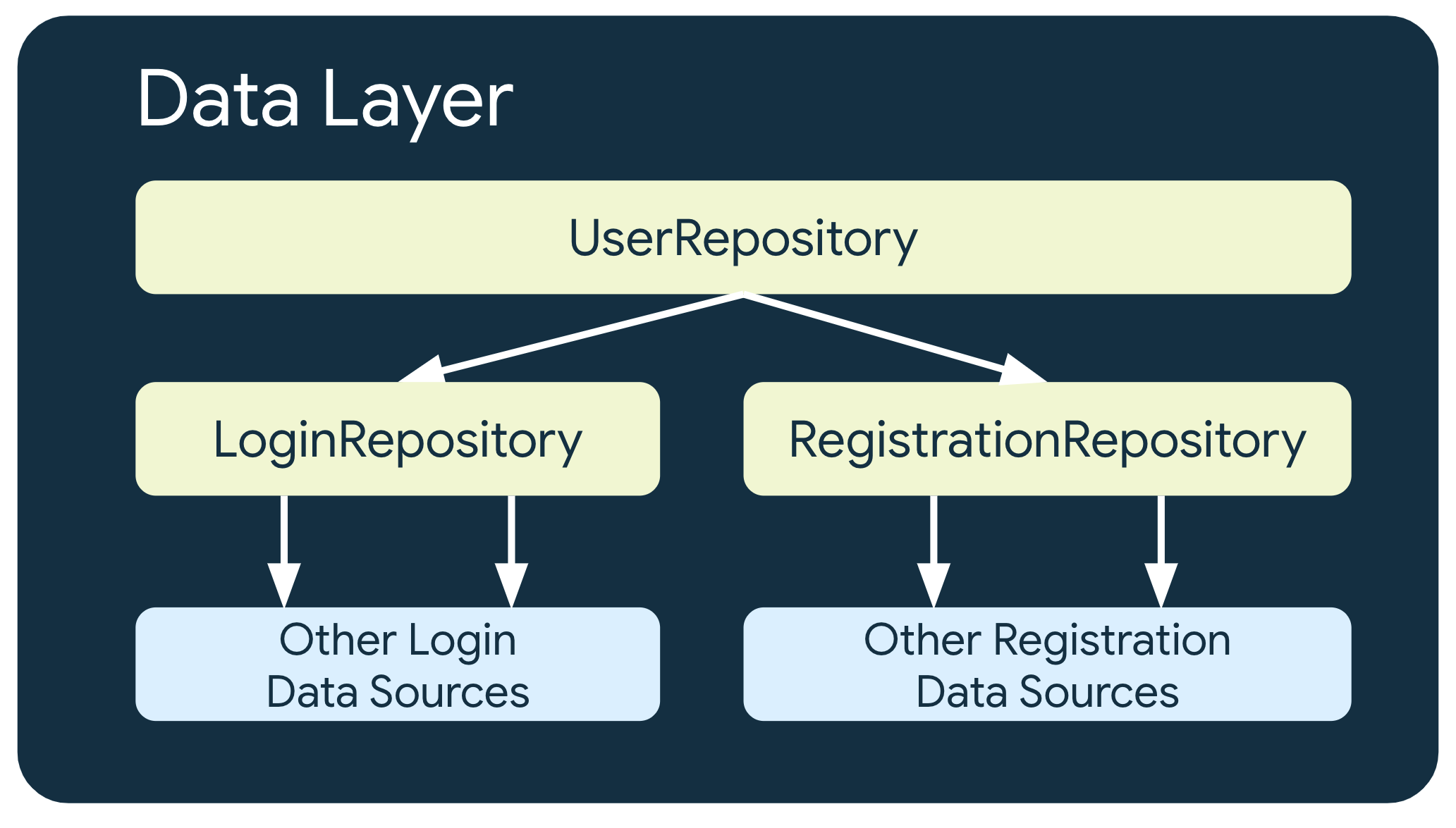
여러 수준의 저장소
더 복잡한 비즈니스 요구사항이 포함된 일부 경우에는 저장소가 다른 저장소에 종속되어야 할 수 있다.
대표 비즈니스 모델
데이터 소스에서 가져오는 정보가 모두 필요한것은 아니다.
모델 클래스를 분리해서 관리하면 좋다.
- 필요한 수준으로 데이터를 줄여 앱 메모리를 절약
- 앱에서 사용하는 데이터 유형에 맞게 외부 데이터 유형을 조정
- 관심사를 분리
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
데이터 소스가 다른곳에서 사용되는 데이터와 일치하지 않는 데이터를 수신한다면 새로운 모델을 만드는 것이 좋다.
구성요소 간 종속 항목 관리
의존성 주입(DI)
클래스가 자신의 종속 항목을 구성할 필요 없이 종속 항목을 정의할 수 있다.
런타임 시 주입
서비스 로케이터
클래스가 자신의 종속 항목을 구성하는 대신 종속 항목을 가져올 수 있는 레지스트리를 제공한다.
아키텍처의 이점
- 앱의 전반적인 유지관리성, 품질, 견고성이 개선된다.
- 앱을 확장할 수 있다. 코드 충돌이 최소화되어 더 많은 인력과 팀이 동일한 코드베이스에 기여할 수 있다.
- 온보딩에 도움이 된다. 프로젝트에 일관성을 부여함으로 새로운 팀원이 빠르게 업무를 시작할 수 있다.
- 테스트하기가 더 쉽다.
- 잘 정의된 프로세스를 사용하여 버그를 체계적으로 조사할 수 있다.